Code
my_wiki_query <- query_wikidata('SELECT ?item ?dob ?dod ?sex_or_gender WHERE {
?item wdt:P31 wd:Q5;
OPTIONAL { ?item wdt:P570 ?dod }
OPTIONAL { ?item wdt:P569 ?dob }
OPTIONAL { ?item wdt:P21 ?sex_or_gender. }
}')“There is only one god and his name is death. And there is only one thing we say to death: Not today.”
― Syrio Forel (Game of Thrones S1:Ep6: A golden crown)
While Game of Thrones fans are fond of refusing the God of Death, Wikipedia has lots of data about people who did say: Ok, today is the day.
In July 2020, my husband presented me with two tweets about change of the average age of death over time (tweet 1 and tweet 2) and challenged me to make some cooler graphs.
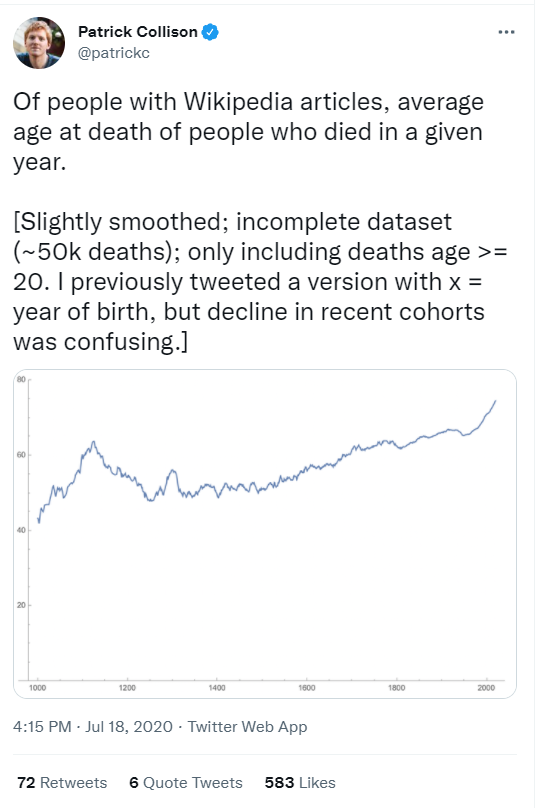
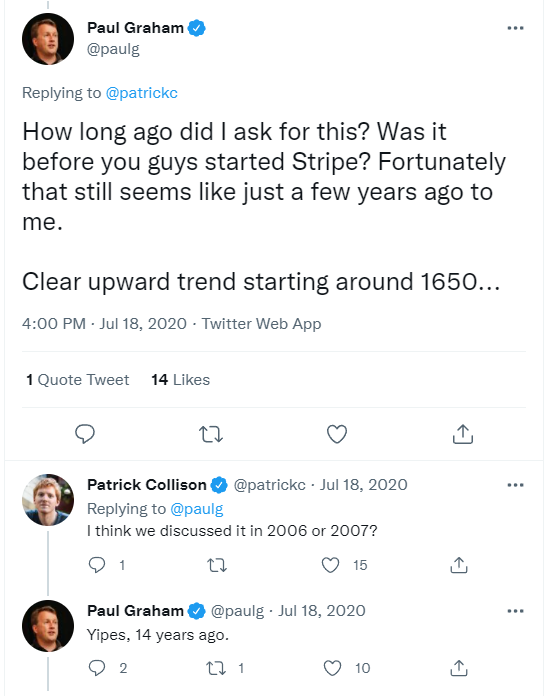
With this post, I want to do three things:
See if I could make more engaging graphs than the original twitter post using R
Learn to pull data from Wikidata using the {WikidataQueryServiceR} package
Visualize the differences between males and females in the data
I work in healthcare data, so often I cannot share my data or analysis for privacy reasons. This post is my way to share some of the techniques I use at work with data that CAN see the light of day.
Here I will walk you start to finish, from data pull to pretty plots, to give you some inspiration for your own data analysis projects.
I originally started working on this analysis and blog post on July 22, 2020, so I have learned a lot of data analytic and programming skills since then, but at the time I had never written a SQL (or one of the many similar SQL-like languages) query outside of an online programming tutorial.
This is the command I used to grab the data from the Wikidata Query Service on November 6, 2021 using the {WikidataQueryServiceR} package.
my_wiki_query <- query_wikidata('SELECT ?item ?dob ?dod ?sex_or_gender WHERE {
?item wdt:P31 wd:Q5;
OPTIONAL { ?item wdt:P570 ?dod }
OPTIONAL { ?item wdt:P569 ?dob }
OPTIONAL { ?item wdt:P21 ?sex_or_gender. }
}')With this short command, I was able to quite effortlessly pull data on 3207218 records.
As I started out learning R and playing with data, I knew nothing about querying publicly available sources of data. Being able to pull over 3 million rows of data for a toy project is an amazing feat!
If you are just starting out in learning R or want to find some great pre-cleaned datasets to work with, check out Tidy Tuesday and follow people’s work on twitter using the #TidyTuesday hashtag.
The first question I had about the distribution of data on time and by year. I decided to limit myself to the year 1000 onward to be somewhat comparable to the tweets that inspired this post. Here I created a plot to show the distribution of births counts by birth year.
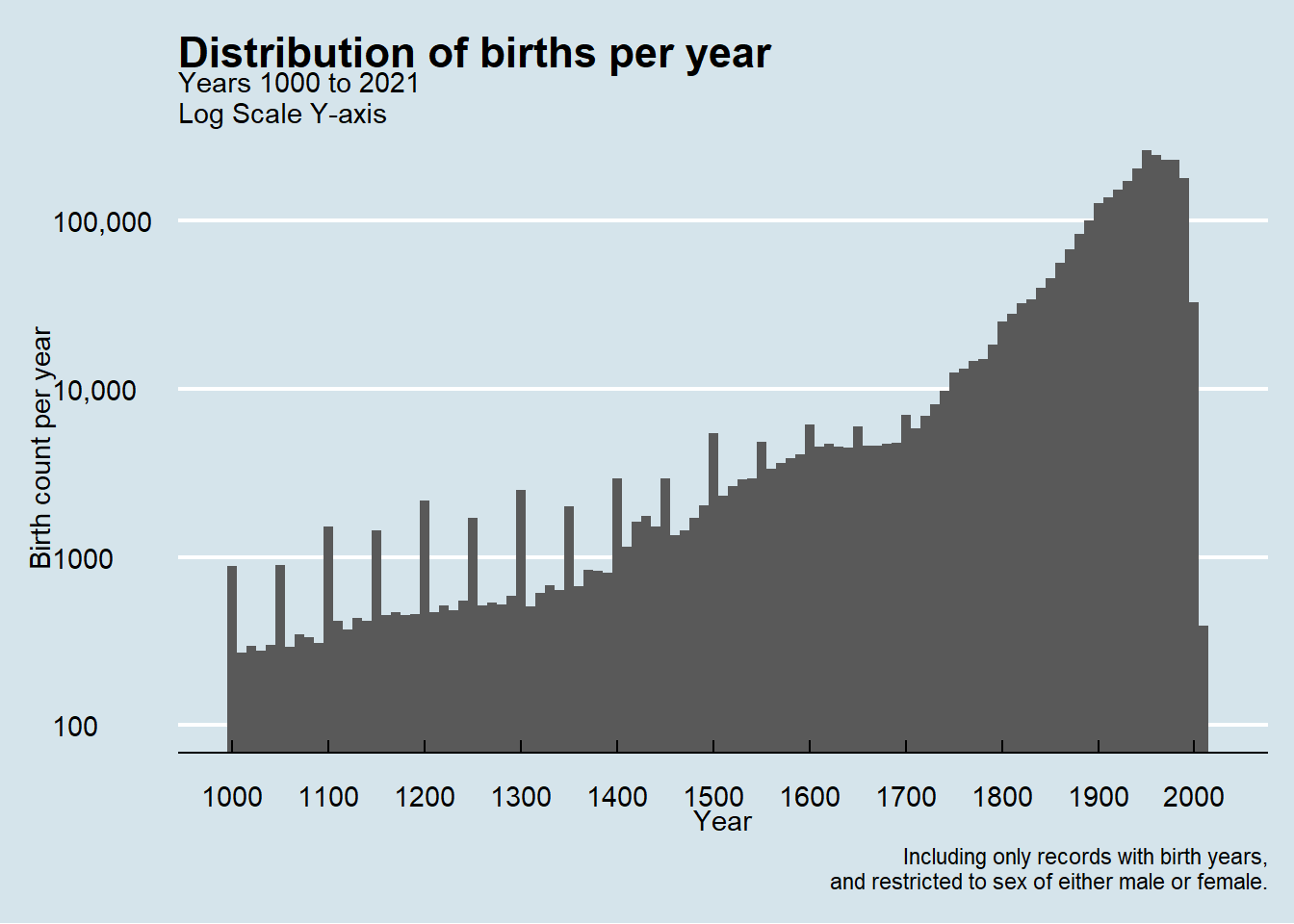
Some notable things about the data is the increase of number of available records over time and with an expected drop off as the birth year gets closer to the current year.
I expected a drop off because it takes most people a certain number of years of life to become notable enough to get a Wikipedia page. While I don’t do this here, I think it would be an interesting analysis to calculate the average age at which a person receives an entry to Wikipedia.
A fun sub-analysis would to examine differences in the ages by category of notability. For example, I expect that athletes would have a younger age of first entry compared to Nobel Laureates.
Another notable trend is that the birth count is high at the start of centuries (eg 1100) compared to intervening years with blunting of that phenomenon from 1500 onward and disappearing around 1800. My instinct is that this reflects the improvement in record keeping and preservation as we approach modern times.
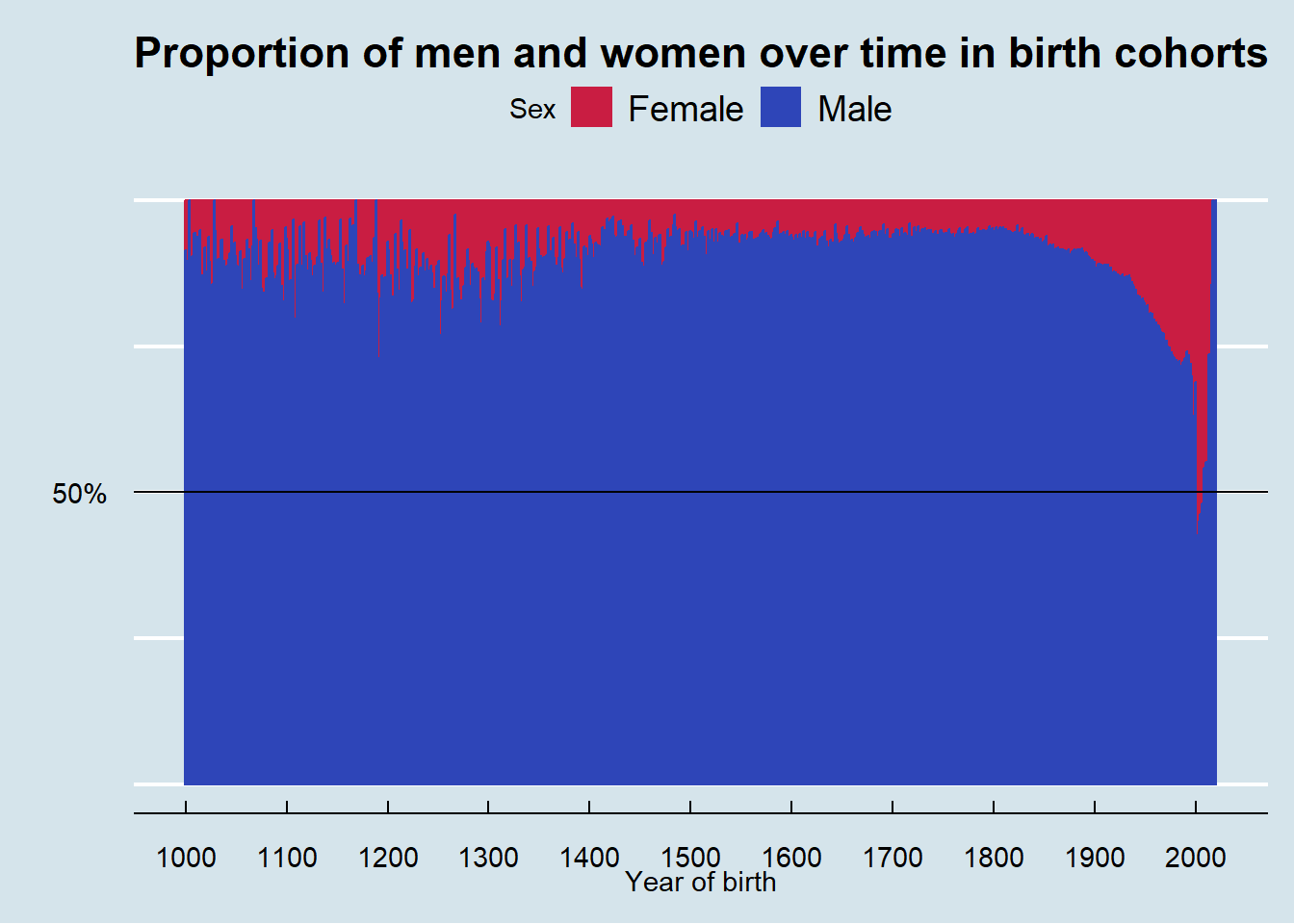
My prediction prior to exploring the distribution is that women are represented at lower rates in the data compared to men. Graphing the data confirms this. I suppose the surprising insight from the graph is that the proportion of women represented in the data from about 1500 to 1800 is so consistent.
I considered two ways to visualize the average of death. The first way is by grouping birth year and seeing the average age of death for that group. As you can see in the graph below, the major issue with that approach is that years close to the present will have very low average ages for death. This happens because in years less than roughly 80 years prior to 2021, anyone who has died, died relatively ‘young’.
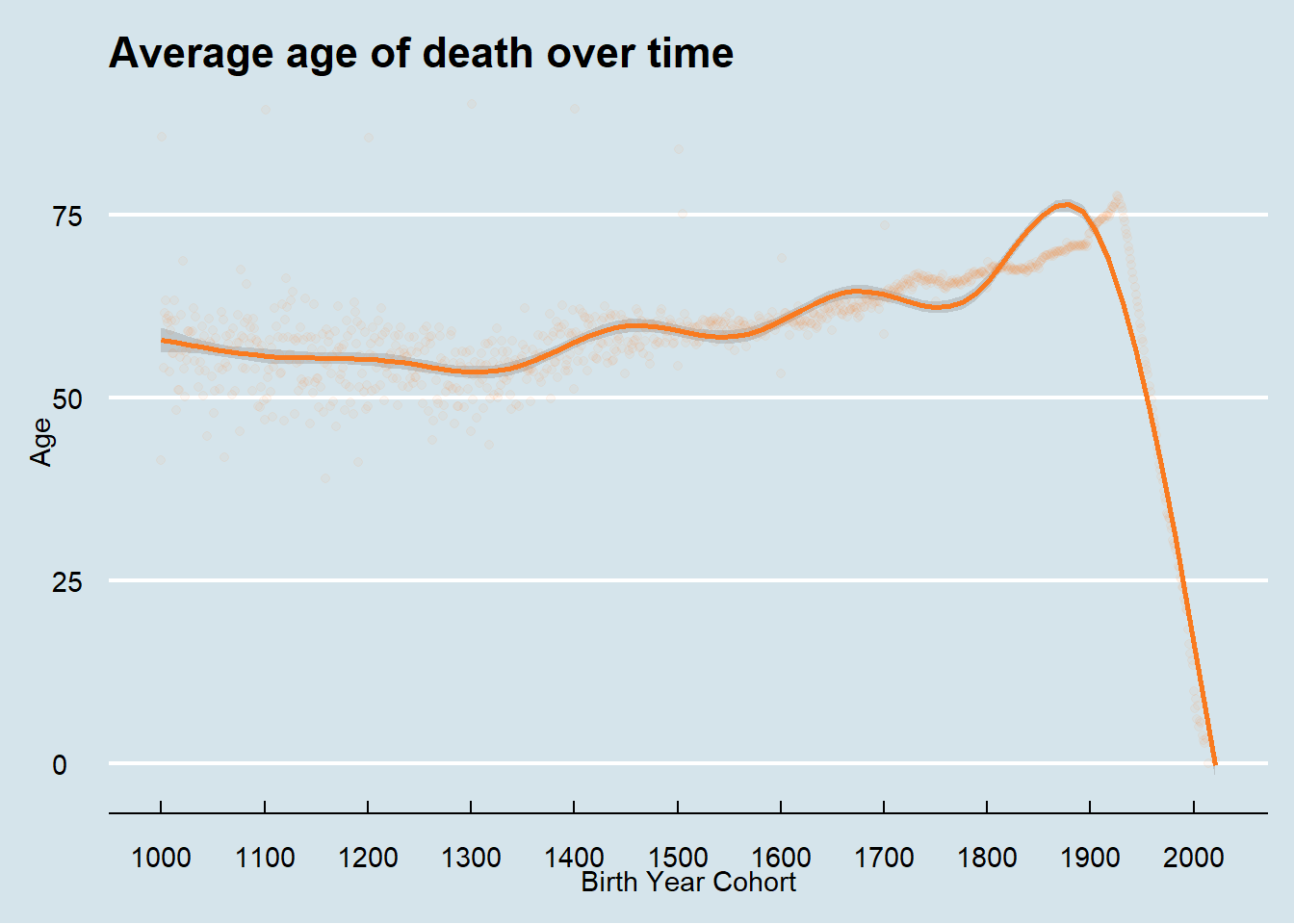
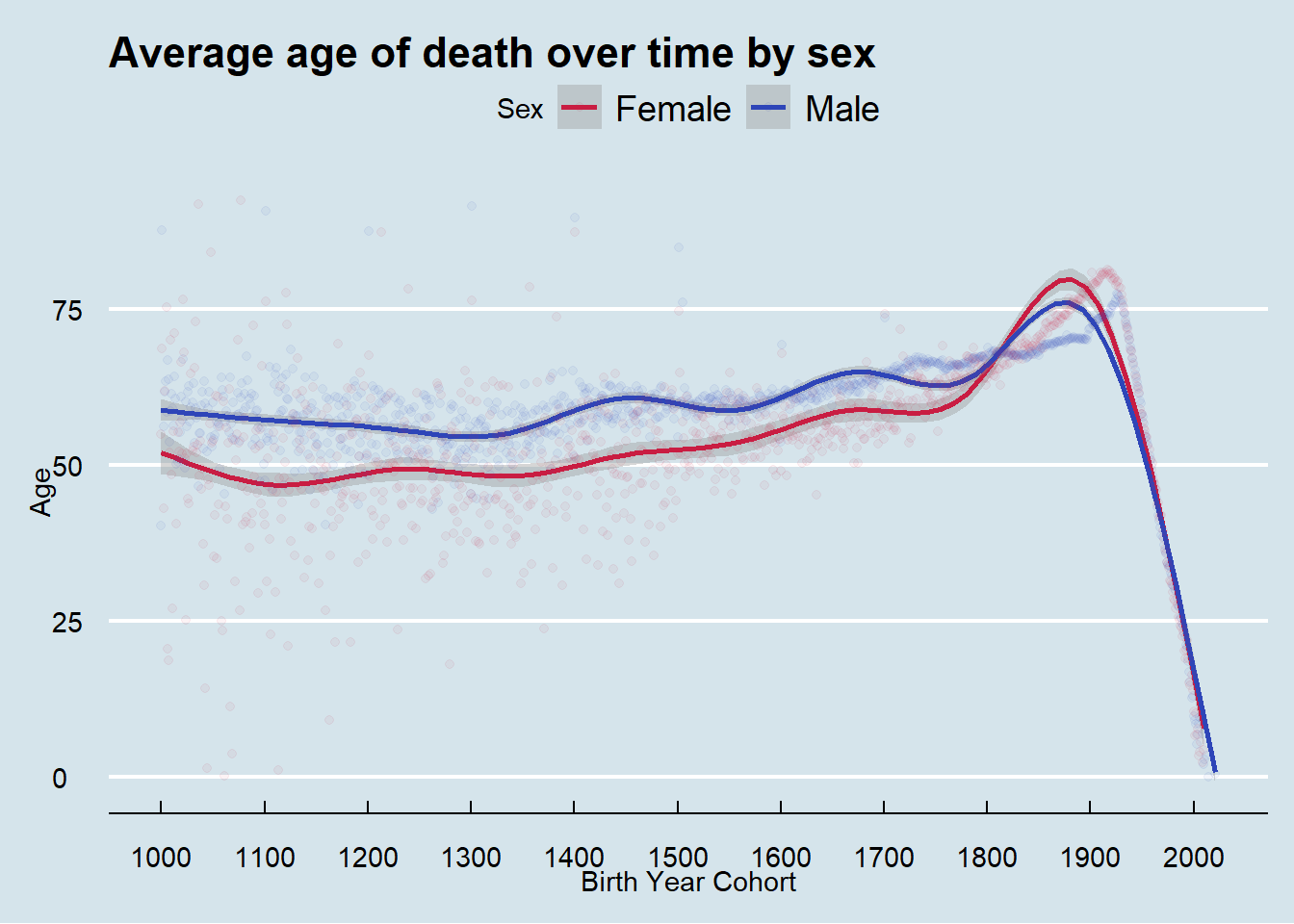
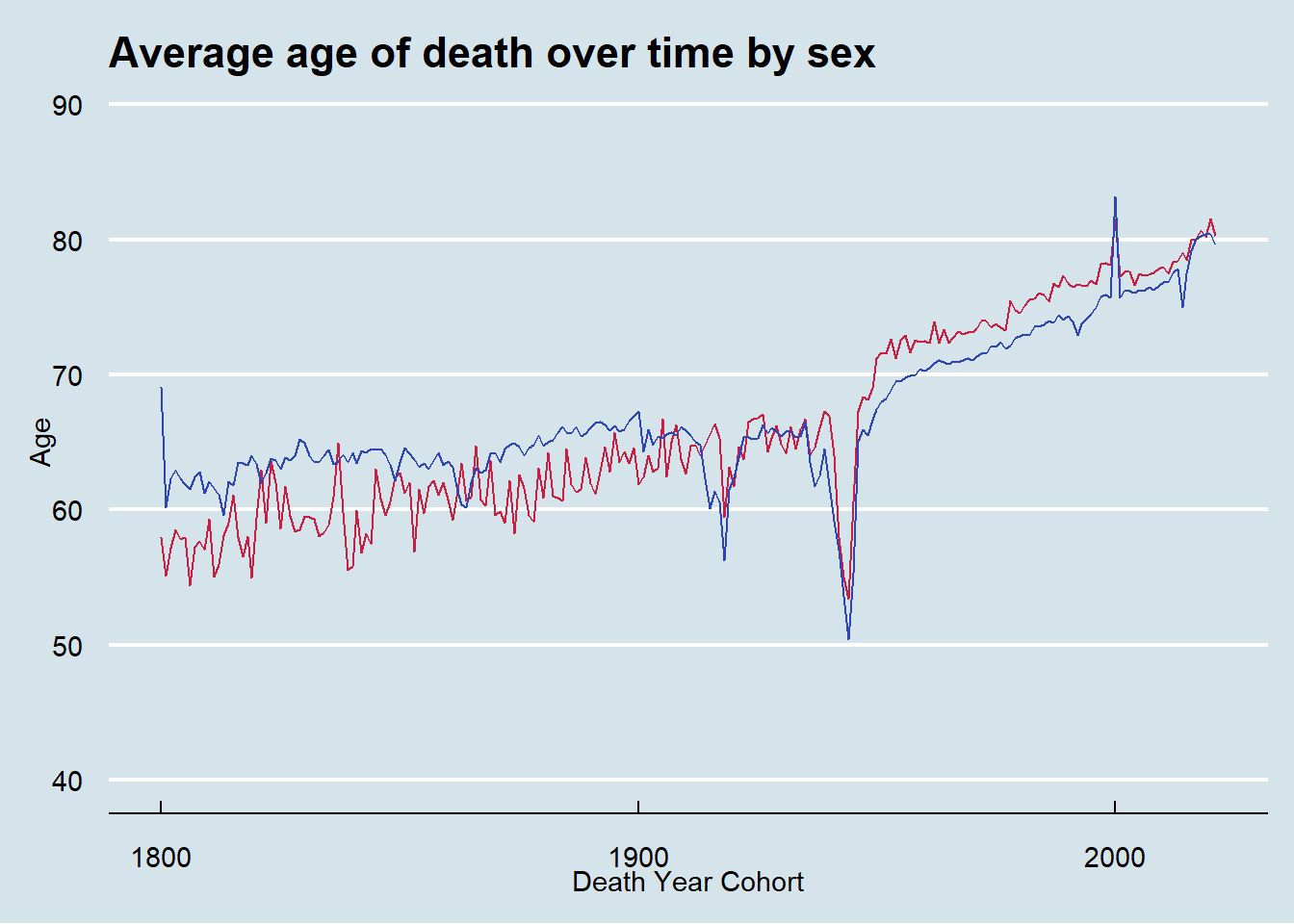
To avoid this problem, I instead grouped by death year to show the average age of death for people who died in that year. From these plots we see the average age of death for women flips to be higher than men in the early 20th century and continues until present time.
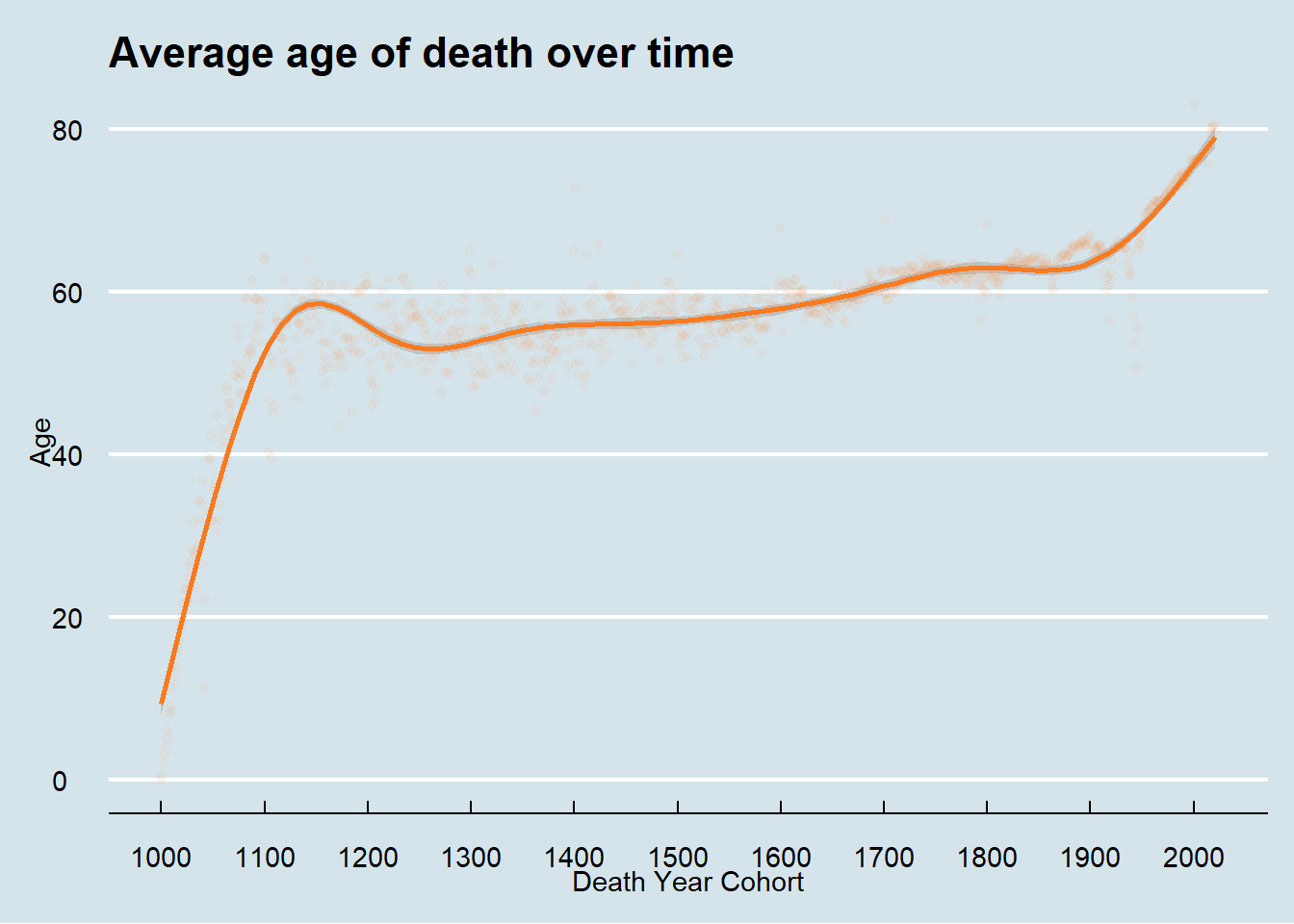
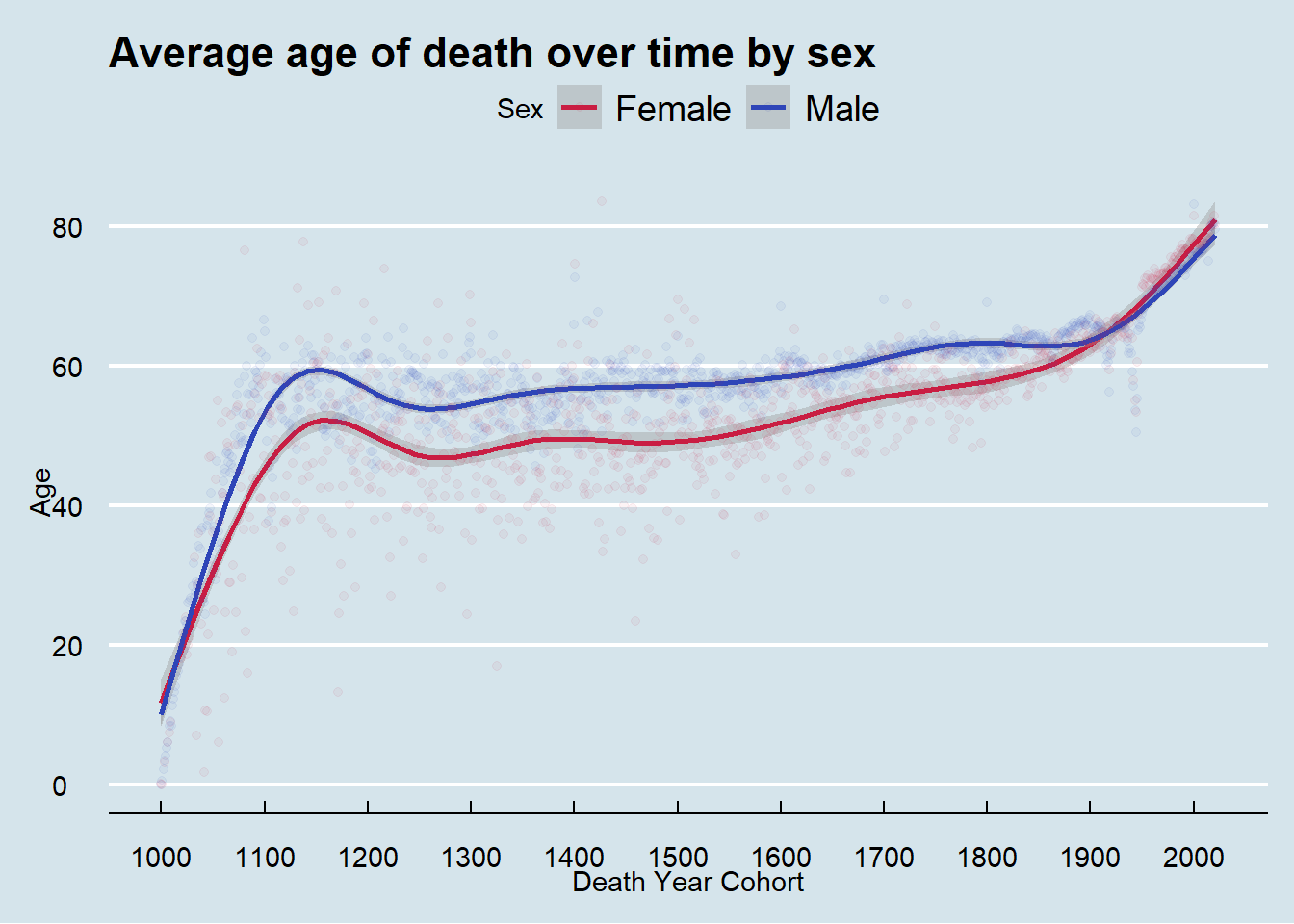
To compare to tweet 1, I need to exclude deaths that occurred at 20 or under. By examining my plot verses that tweet, it is difficult to compare because I don’t know what smoothing function that the person used to calculate their line. The data before about 1600 has much more variability that data after that point.
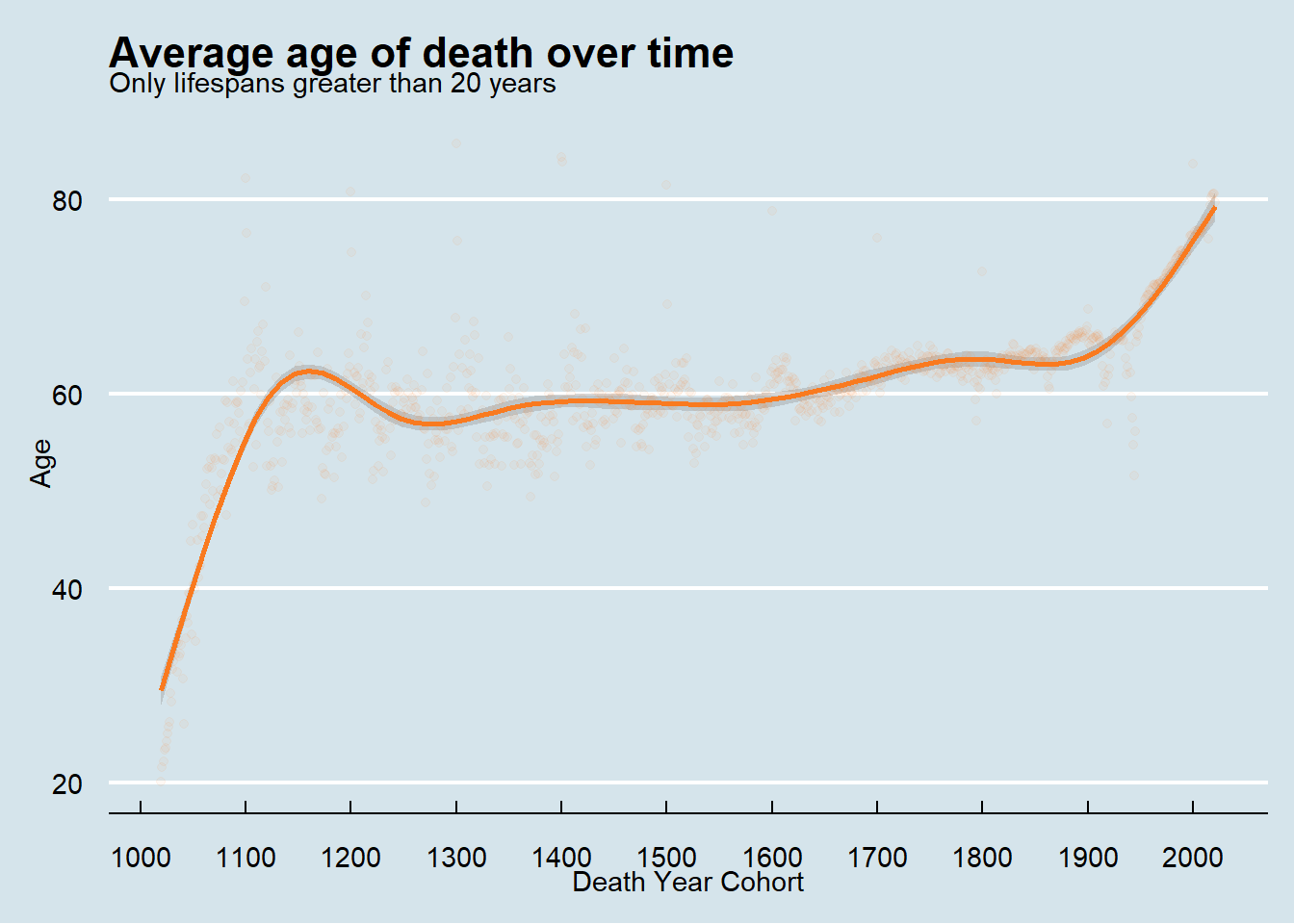
Given this, I then investigated what the average age of death looks like from 1600 onward.
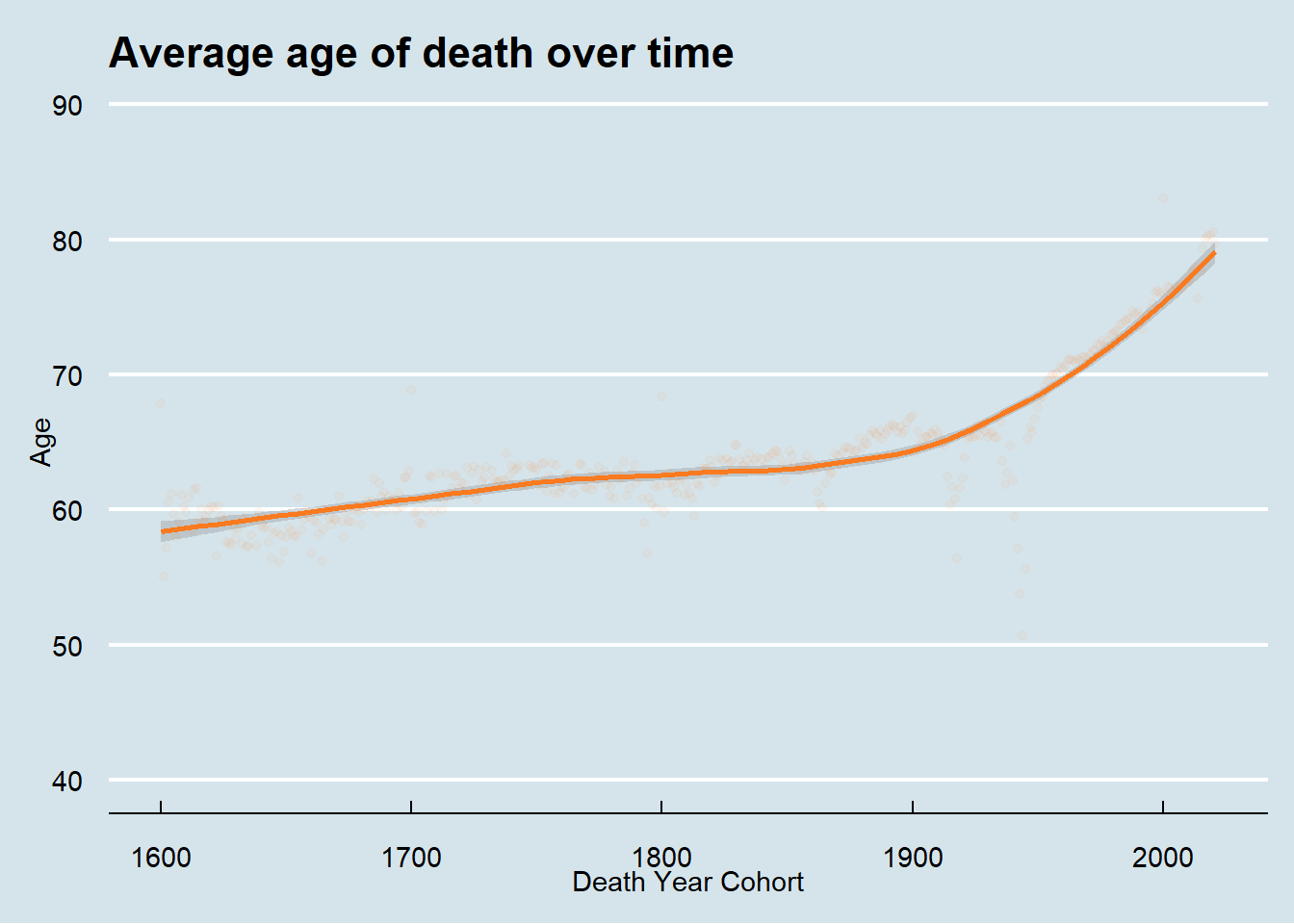
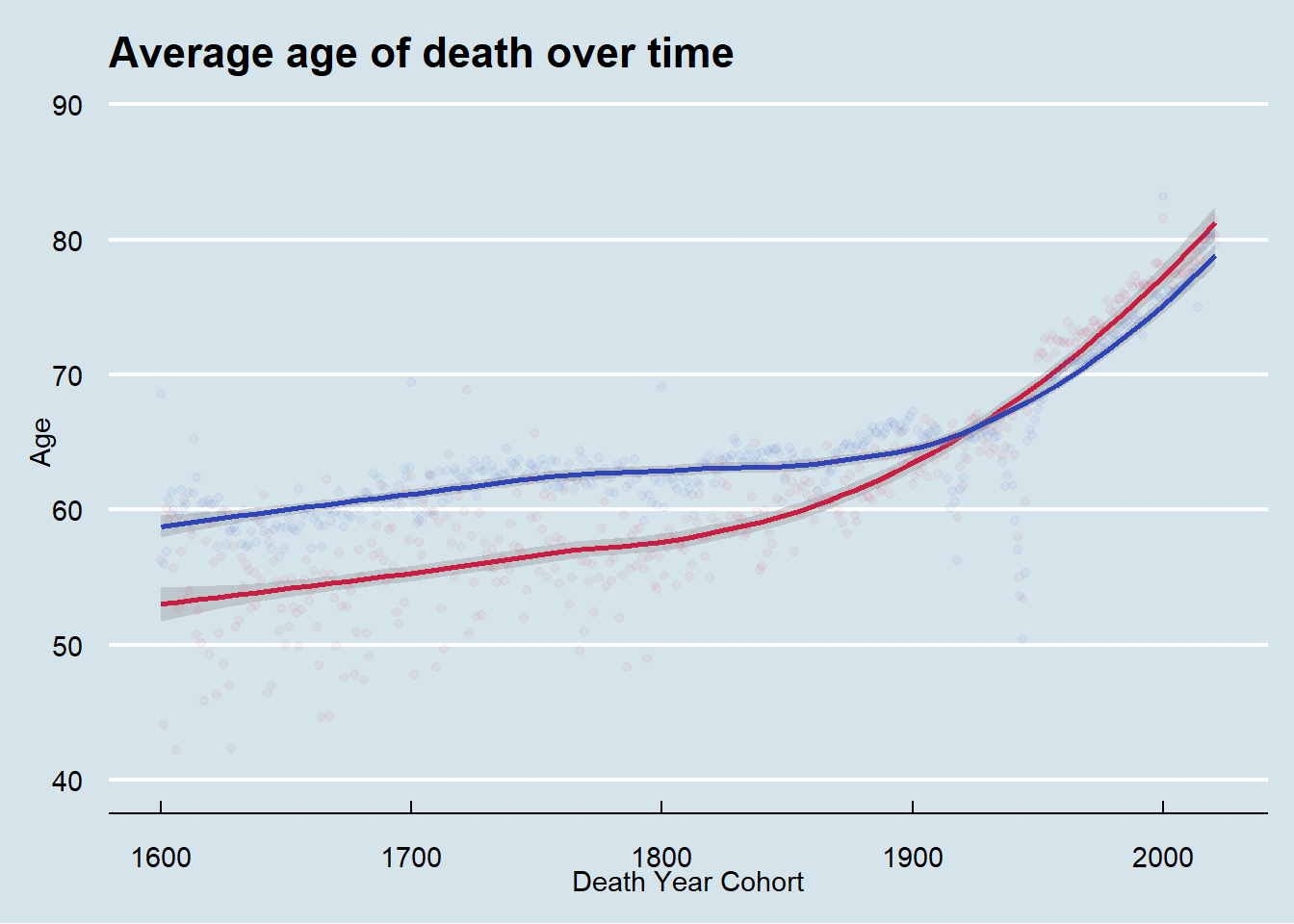
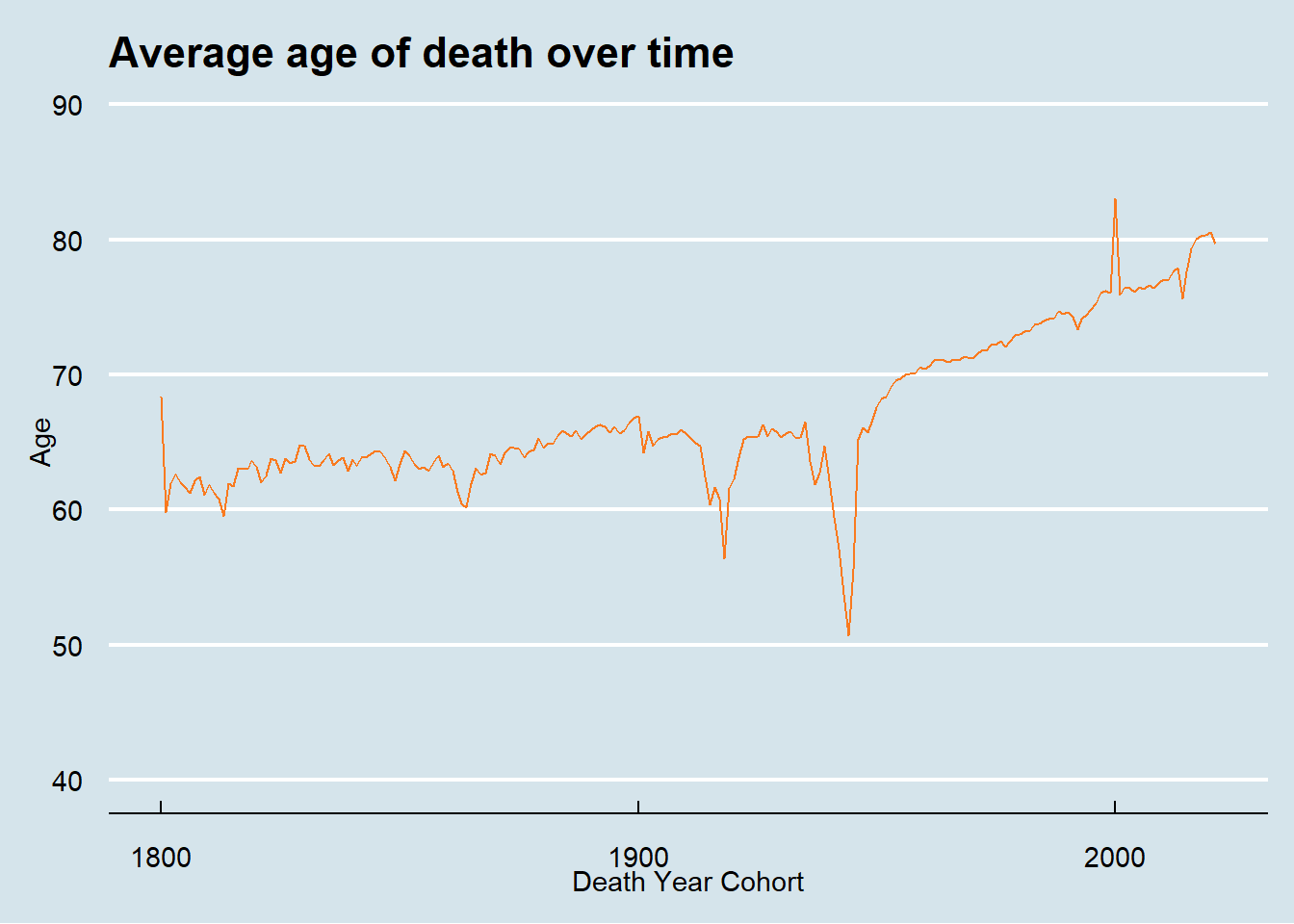
Finally, let’s look at the data from 1800 onward to investigate the huge expected impacts of both World Wars. While I expected to see the huge impact on age of death in the years 1914 - 1918 and 1939 - 1945, I was surprised to see that the average age of death for both men and women was so affected. I anticipated that men, who are the primary actors in military actions, would have taken a bigger hit than women. While beyond the scope of this post, I think there might be something mysterious going on in the data around the turn of the 21st century with a spike upwards in both sex’s average age of death.
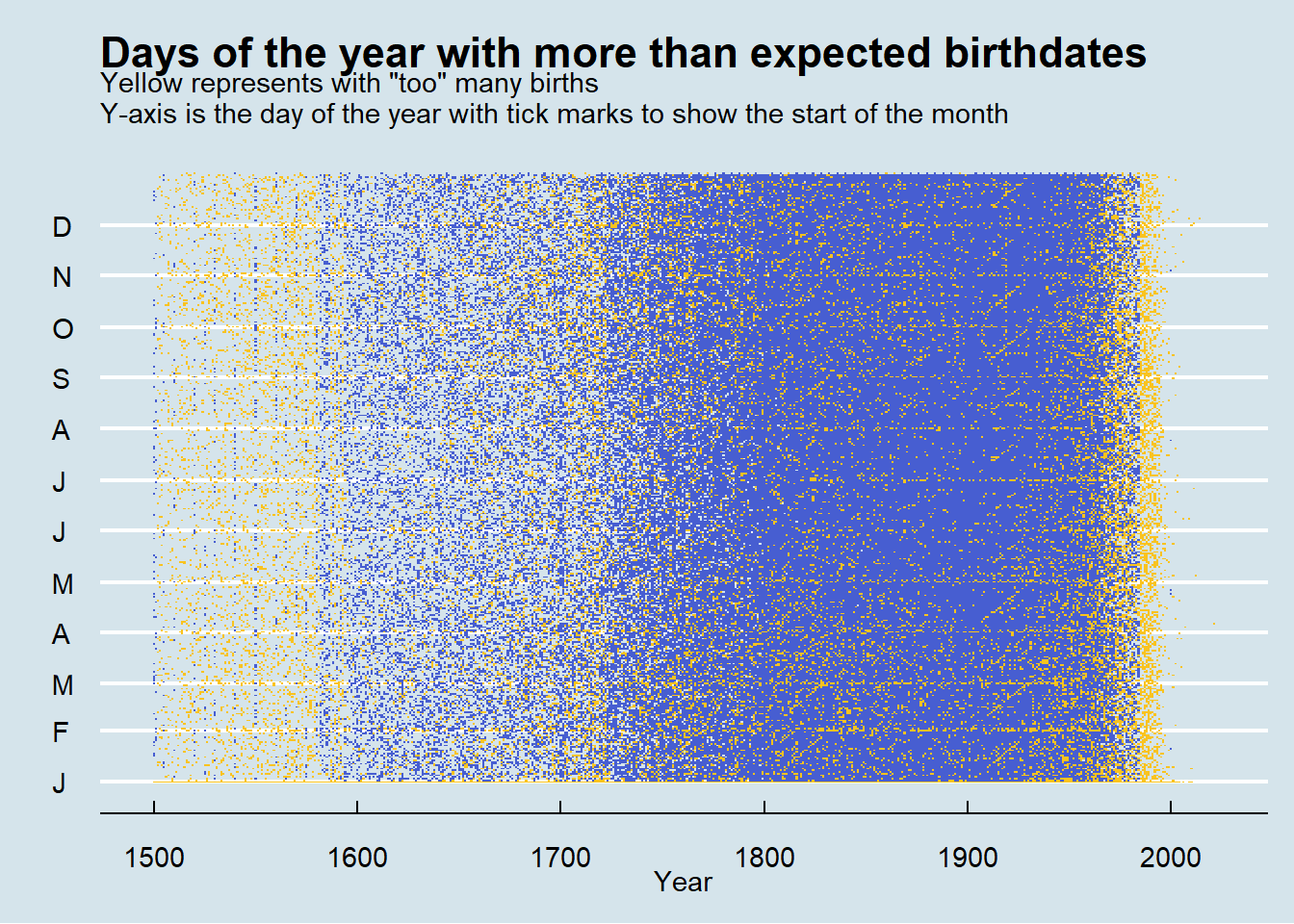
Speaking of data issues, the final part of my analysis I’d like to share is how many birth dates are represented at higher rates than expected. As mentioned above, before 1800, many people had birth years listed as years like 1000 or 1300. Here I’ll also show how uncertainty of the day of births can be seen in the data.
The plot below shows a yellow dot for date that has a 10% or greater number of birth dates than expected under the (somewhat tenuous) assumption that birth days will be distributed equally throughout the year. Notice the nearly straight lines on the y-axis which represents birth dates that fall on the start of a month.
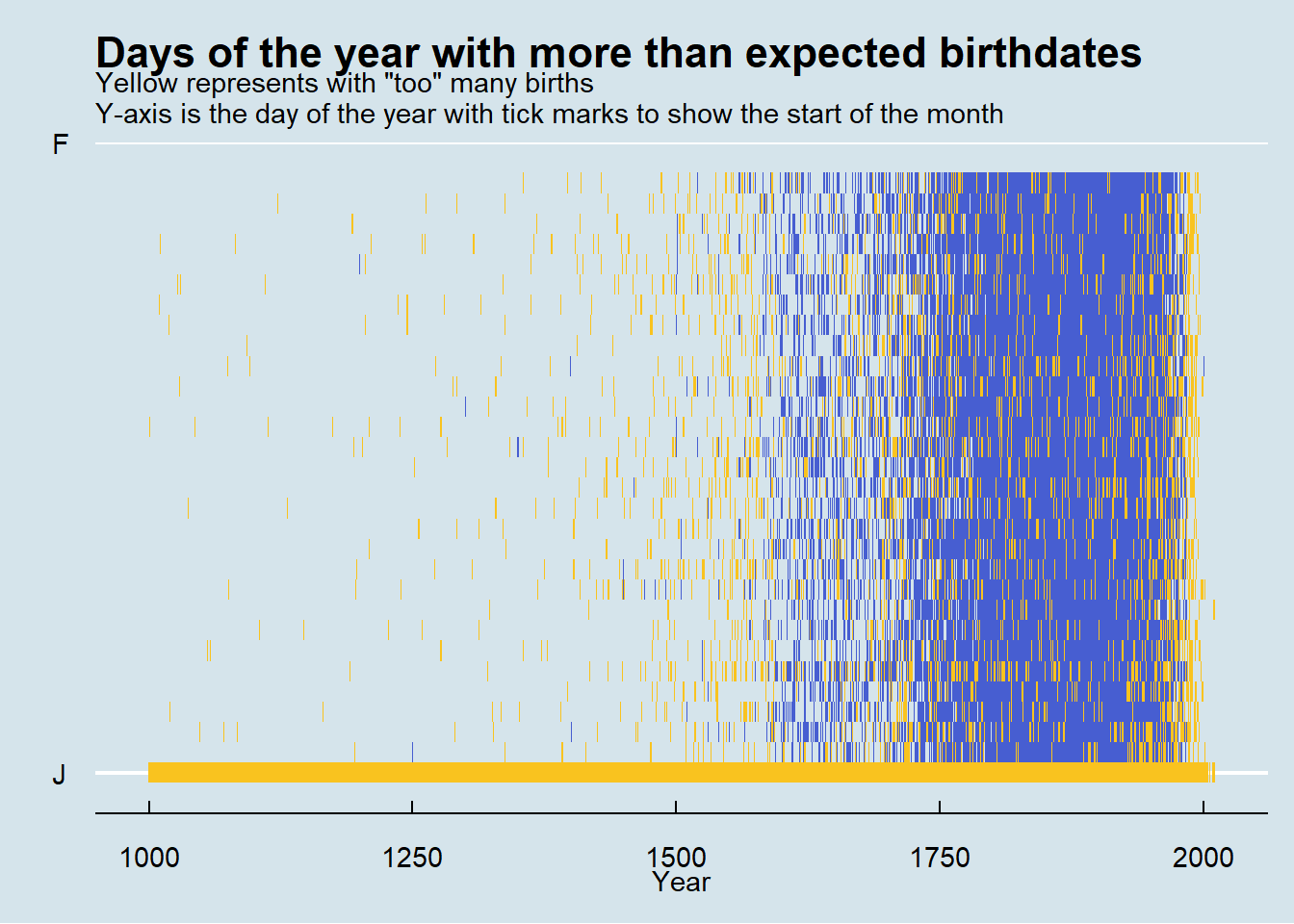
Difficult to see on the graph above, but here is a zoomed in version looking only at January birth dates. Here you can see that January 1st is over-represented in the data for literally ever year in the data from 1000 to 2021!
I hope you have enjoyed my mini-journey of exploring the average age of the death over time. It only took me 17 months to finally finish it!
What I hope I can do in future posts is look at data for people beyond those notable enough to have Wikidata entries to see the difference in life expectancies for those more and less notable.
For anyone wanting to reproduce my work, you can see my raw code below as well as my R session information. If you repeat the analysis, your data will likely be different than mine as the data pull for this post was done on November 6, 2021.
library(tidyverse)
library(WikidataQueryServiceR)
library(lubridate)
library(stringr)
library(magrittr)
library(plotly)
library(DT)
library(scales)
library(ggthemes)
my_wiki_query <- query_wikidata('SELECT ?item ?dob ?dod ?sex_or_gender WHERE {
?item wdt:P31 wd:Q5;
OPTIONAL { ?item wdt:P570 ?dod }
OPTIONAL { ?item wdt:P569 ?dob }
OPTIONAL { ?item wdt:P21 ?sex_or_gender. }
}')
my_wiki_query <- readRDS("./data/my_wiki_query.rds")
count_query <- nrow(my_wiki_query)
# sex notation
my_wiki_query %<>%
mutate(simplified_sex = case_when(
sex_or_gender == "http://www.wikidata.org/entity/Q6581072" ~ 1, #female
sex_or_gender == "http://www.wikidata.org/entity/Q6581097" ~ 2, #male
TRUE ~ 3 #not female, not male
))
my_wiki_query %<>%
dplyr::distinct(item, .keep_all= TRUE) %>%
dplyr::mutate(full_year_of_birth = str_extract(dob, "-?[:digit:]{4}")) %>%
dplyr::mutate(full_year_of_death = str_extract(dod, "-?[:digit:]{4}")) %>%
dplyr::mutate(approx_age_at_death = as.numeric(full_year_of_death) - as.numeric(full_year_of_birth))
my_wiki_query$full_year_of_birth <- as.numeric(my_wiki_query$full_year_of_birth)
my_wiki_query$full_year_of_death <- as.numeric(my_wiki_query$full_year_of_death)
my_wiki_query$simplified_sex <- as_factor(my_wiki_query$simplified_sex)
my_wiki_query %<>% mutate(decade_birth = full_year_of_birth %/% 10)
my_wiki_query %>%
filter(full_year_of_birth >= 1000 & full_year_of_birth < 2022) %>%
filter(simplified_sex == 1 | simplified_sex == 2) %>%
ggplot(aes(x = full_year_of_birth)) +
geom_histogram(binwidth = 10) +
scale_y_log10(breaks=c(100, 1000, 10000, 100000), labels = c("100", "1000", "10,000", "100,000")) +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
theme_economist() +
labs(title = "Distribution of births per year",
x = "Year",
y = "Birth count per year",
subtitle = "Years 1000 to 2021\nLog Scale Y-axis",
caption = "Including only records with birth years,\nand restricted to sex of either male or female.") +
coord_cartesian(ylim = c(100, 200000))
male_color <- "#2E45B8"
female_color <- "#C91D42"
sex_proportion_plot <- my_wiki_query %>%
filter(simplified_sex == 1 | simplified_sex == 2) %>%
filter(full_year_of_birth >= 1000 & full_year_of_birth < 2021) %>%
# group_by(decade_birth) %>%
ggplot(aes(x = full_year_of_birth, fill = simplified_sex, color = simplified_sex)) +
geom_bar(position = "fill") +
scale_fill_manual(labels = c("Female", "Male"), values = c(female_color, male_color)) +
scale_color_manual(labels = c("Female", "Male"), values = c(female_color, male_color)) +
labs(title = "Proportion of men and women over time in birth cohorts",
x = "Year of birth",
y = " ",
fill = "Sex",
color = NULL) +
geom_hline(yintercept = 0.5) +
theme_economist() +
scale_y_continuous(breaks=c(0, 0.25, .5, 0.75, 1),
labels = c(" ", " ", "50%", " ", " ")) +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
guides(color = "none")
sex_proportion_plot
ce_dates <- my_wiki_query %>%
filter(full_year_of_birth >= 1000 & full_year_of_birth <= 2021) %>%
filter(full_year_of_death >= 1000 & full_year_of_birth <= 2021) %>%
mutate(date_of_birth = as_date(dob)) %>%
mutate(year_birth = year(date_of_birth)) %>%
mutate(month_birth = month(date_of_birth)) %>%
mutate(day_birth = day(date_of_birth)) %>%
mutate(date_of_death = as_date(dod)) %>%
mutate(year_death = year(date_of_death)) %>%
mutate(month_death = month(date_of_death)) %>%
mutate(day_death = day(date_of_death)) %>%
mutate(lifespan = as.duration(interval(date_of_birth, date_of_death))) %>%
filter(lifespan < years(123)) %>%
filter(lifespan >= years(0))
average_lifespan_by_sex <- ce_dates %>%
group_by(year_birth, simplified_sex) %>%
summarise(average_age = mean((lifespan)))
average_lifespan <- ce_dates %>%
group_by(year_birth) %>%
summarise(average_age = mean((lifespan)))
plot_average_lifespan <- average_lifespan %>%
ggplot(aes(x = year_birth, y = (average_age/31557600))) +
geom_smooth(color = "#F97A1F") +
geom_point(alpha = 0.05, color = "#F97A1F") +
labs(title = "Average age of death over time",
x = "Birth Year Cohort",
y = "Age")
plot_average_lifespan + theme_economist() + scale_x_continuous(breaks = seq(1000, 2021, 100))
average_lifespan_by_sex <- ce_dates %>%
group_by(year_birth, simplified_sex) %>%
summarise(average_age = mean((lifespan)))
plot_average_lifespan_by_sex <- average_lifespan_by_sex %>%
filter(simplified_sex != 3) %>%
ggplot(aes(x = year_birth, y = (average_age/31557600), color = simplified_sex)) +
geom_smooth() +
geom_point(alpha = 0.05) +
scale_color_manual(labels = c("Female", "Male"), values = c(female_color, male_color)) +
labs(title = "Average age of death over time by sex",
x = "Birth Year Cohort",
y = "Age",
color = "Sex")
plot_average_lifespan_by_sex + theme_economist() + scale_x_continuous(breaks = seq(1000, 2021, 100))
average_lifespan_by_sex_dc <- ce_dates %>%
group_by(year_death, simplified_sex) %>%
summarise(average_age = mean((lifespan)))
average_lifespan_dc <- ce_dates %>%
group_by(year_death) %>%
summarise(average_age = mean((lifespan)))
plot_average_lifespan_dc <- average_lifespan_dc %>%
ggplot(aes(x = year_death, y = (average_age/31557600))) +
geom_smooth(color = "#F97A1F") +
geom_point(alpha = 0.05, color = "#F97A1F") +
labs(title = "Average age of death over time",
x = "Death Year Cohort",
y = "Age")
plot_average_lifespan_dc + theme_economist() + scale_x_continuous(breaks = seq(1000, 2021, 100))
plot_average_lifespan_by_sex_dc <- average_lifespan_by_sex_dc %>%
filter(simplified_sex != 3) %>%
ggplot(aes(x = year_death, y = (average_age/31557600), color = simplified_sex)) +
geom_smooth() +
geom_point(alpha = 0.05) +
scale_color_manual(labels = c("Female", "Male"), values = c(female_color, male_color)) +
labs(title = "Average age of death over time by sex",
x = "Death Year Cohort",
y = "Age",
color = "Sex")
plot_average_lifespan_by_sex_dc + theme_economist() + scale_x_continuous(breaks = seq(1000, 2021, 100))
average_lifespan_dc_20 <- ce_dates %>%
filter(lifespan > 630720000) %>%
group_by(year_death) %>%
summarise(average_age = mean((lifespan)))
plot_average_lifespan_dc_20 <- average_lifespan_dc_20 %>%
ggplot(aes(x = year_death, y = (average_age/31557600))) +
geom_smooth(color = "#F97A1F") +
geom_point(alpha = 0.05, color = "#F97A1F") +
labs(title = "Average age of death over time",
subtitle = "Only lifespans greater than 20 years",
x = "Death Year Cohort",
y = "Age")
plot_average_lifespan_dc_20 + theme_economist() + scale_x_continuous(breaks = seq(1000, 2021, 100))
plot_average_lifespan_dc <- average_lifespan_dc %>%
filter(year_death >= 1600) %>%
ggplot(aes(x = year_death, y = (average_age/31557600))) +
geom_smooth(color = "#F97A1F") +
geom_point(alpha = 0.05, color = "#F97A1F") +
labs(title = "Average age of death over time",
x = "Death Year Cohort",
y = "Age")
plot_average_lifespan_dc +
theme_economist() +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
coord_cartesian(ylim = c(40, 90))
plot_average_lifespan_by_sex_dc <- average_lifespan_by_sex_dc %>%
filter(year_death >= 1600) %>%
filter(simplified_sex != 3) %>%
ggplot(aes(x = year_death, y = (average_age/31557600), color = simplified_sex)) +
geom_smooth() +
geom_point(alpha = 0.05) +
scale_color_manual(labels = c("Female", "Male"), values = c(female_color, male_color)) +
labs(title = "Average age of death over time",
x = "Death Year Cohort",
y = "Age",
color = "Sex") +
guides(color = "none")
plot_average_lifespan_by_sex_dc +
theme_economist() +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
coord_cartesian(ylim = c(40, 90))
year_cutoff <- 1800
plot_average_lifespan_dc <- average_lifespan_dc %>%
filter(year_death >= year_cutoff) %>%
ggplot(aes(x = year_death, y = (average_age/31557600))) +
geom_line(color = "#F97A1F") +
# geom_point(alpha = 0.05, color = "#F97A1F") +
labs(title = "Average age of death over time",
x = "Death Year Cohort",
y = "Age")
plot_average_lifespan_dc +
theme_economist() +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
coord_cartesian(ylim = c(40, 90))
plot_average_lifespan_by_sex_dc <- average_lifespan_by_sex_dc %>%
filter(year_death >= year_cutoff) %>%
filter(simplified_sex != 3) %>%
ggplot(aes(x = year_death, y = (average_age/31557600), color = simplified_sex)) +
geom_line() +
scale_color_manual(labels = c("Female", "Male"), values = c(female_color, male_color)) +
labs(title = "Average age of death over time by sex",
x = "Death Year Cohort",
y = "Age",
color = "Sex") +
guides(color = "none")
plot_average_lifespan_by_sex_dc +
theme_economist() +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
coord_cartesian(ylim = c(40, 90))
heatmap_dates <- ce_dates %>%
mutate(pad_month_birth = str_pad(month_birth, width = 2, side = "left", pad = 0)) %>%
mutate(pad_day_birth = str_pad(day_birth, width = 2, side = "left", pad = 0)) %>%
unite("heatdate", c(year_birth, pad_month_birth, pad_day_birth), sep = "-", remove = FALSE) %>%
mutate(doy = lubridate::yday(as_date(heatdate)))
heatmap_dates_subset <- heatmap_dates %>% dplyr::select(year_birth, heatdate, doy)
heatmap_data <- heatmap_dates_subset %>%
group_by(year_birth, doy) %>%
summarise(count = n()) %>%
ungroup() %>%
group_by(year_birth) %>%
mutate(year_total = sum(count)) %>%
mutate(proportion_year = count/year_total) %>%
mutate(too_high = case_when(
proportion_year > 0.003 ~ 1, #roughly 10% higher than expected
TRUE ~ 0
))
too_many_births_plot <- heatmap_data %>%
filter(year_birth >= 1500) %>%
ggplot(aes(x = year_birth, y = doy, fill = too_high, text = )) +
geom_tile() +
scale_fill_gradient(low = "#475ED1", high = "#F9C31F") + # mid
theme_economist() +
theme(legend.position = "none") +
labs(x = "Year",
y = " ",
title = "Days of the year with more than expected birthdates",
subtitle = "Yellow represents with \"too\" many births \nY-axis is the day of the year with tick marks to show the start of the month") +
scale_y_continuous(breaks=c(1, 32, 60, 91, 121, 152, 182, 213, 244, 274, 305, 335),
labels = c("J", "F", "M", "A", "M", "J", "J", "A", "S", "O", "N", "D"))
too_many_births_plot
too_many_births_plot <- heatmap_data %>%
filter(doy < 31) %>%
ggplot(aes(x = year_birth, y = doy, fill = too_high, text = )) +
geom_tile() +
scale_fill_gradient(low = "#475ED1", high = "#F9C31F") + # mid
theme_economist() +
theme(legend.position = "none") +
labs(x = "Year",
y = " ",
title = "Days of the year with more than expected birthdates",
subtitle = "Yellow represents with \"too\" many births \nY-axis is the day of the year with tick marks to show the start of the month") +
scale_y_continuous(breaks=c(1, 32, 60, 91, 121, 152, 182, 213, 244, 274, 305, 335),
labels = c("J", "F", "M", "A", "M", "J", "J", "A", "S", "O", "N", "D"))
too_many_births_plot
sessionInfo()
image_for_blog_post <- plot_average_lifespan_by_sex_dc +
theme_economist() +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
coord_cartesian(ylim = c(40, 90))
ggsave(file = "./images/image_for_blog_post.png" )sessionInfo()R version 4.4.2 (2024-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26100)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/New_York
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggthemes_5.1.0 scales_1.4.0
[3] DT_0.33 plotly_4.11.0
[5] magrittr_2.0.3 WikidataQueryServiceR_1.0.0
[7] lubridate_1.9.4 forcats_1.0.0
[9] stringr_1.5.2 dplyr_1.1.4
[11] purrr_1.0.4 readr_2.1.5
[13] tidyr_1.3.1 tibble_3.2.1
[15] ggplot2_3.5.2 tidyverse_2.0.0
loaded via a namespace (and not attached):
[1] generics_0.1.4 lattice_0.22-6 stringi_1.8.4 hms_1.1.3
[5] digest_0.6.37 evaluate_1.0.3 grid_4.4.2 timechange_0.3.0
[9] RColorBrewer_1.1-3 fastmap_1.2.0 Matrix_1.7-1 jsonlite_2.0.0
[13] httr_1.4.7 mgcv_1.9-1 viridisLite_0.4.2 lazyeval_0.2.2
[17] cli_3.6.4 rlang_1.1.5 splines_4.4.2 withr_3.0.2
[21] yaml_2.3.10 tools_4.4.2 tzdb_0.5.0 ratelimitr_0.4.2
[25] assertthat_0.2.1 vctrs_0.6.5 R6_2.6.1 lifecycle_1.0.4
[29] htmlwidgets_1.6.4 pkgconfig_2.0.3 pillar_1.10.2 gtable_0.3.6
[33] glue_1.8.0 data.table_1.17.6 xfun_0.52 tidyselect_1.2.1
[37] rstudioapi_0.17.1 knitr_1.50 farver_2.1.2 nlme_3.1-166
[41] htmltools_0.5.8.1 labeling_0.4.3 rmarkdown_2.29 compiler_4.4.2 image_for_blog_post <- plot_average_lifespan_by_sex_dc +
theme_economist() +
scale_x_continuous(breaks = seq(1000, 2021, 100)) +
coord_cartesian(ylim = c(40, 90))
ggsave(file = "./images/image_for_blog_post.png" )Saving 7 x 5 in image